一年多来,我们一直期待Amazon Web Services在今年的re:Invent大会上为其本土服务器推出 Graviton4 处理器。正如预期,AWS首席执行官Adam Selipsky推出了第四代 Graviton CPU系列,包括去年针对HPC工作负载的超频Graviton3E处理器。
Selipsky在主题演讲期间没有强制举起Graviton4 芯片,这很奇怪。但新闻稿中确实包含了一张芯片照片,如上面的特征图片所示。
Graviton4 提高了各种工作负载的性价比和能效标准
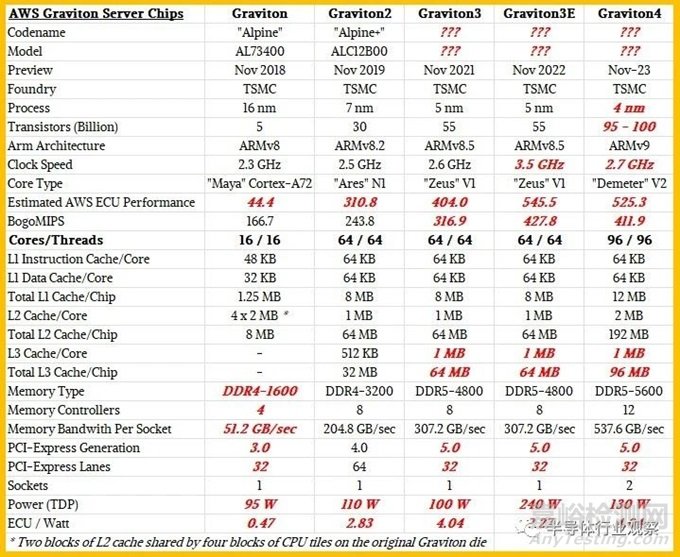
正如我们所预料的那样,Graviton4 也基于 Arm Ltd 的“Demeter”Neoverse V2 内核,该内核与 Nvidia 的“Grace”CG100 CPU 一样基于 Armv9 架构。(Nvidia 官方并没有给 Grace 一个与其 GPU 命名方案一致的产品名称,所以我们就暂且这样命名。C代表CPU,G代表Grace。)我们在2017年对Demeter V2核心进行了深入研究。9月份,Arm发布了“Genesis”计算子系统,与之前由AWS部署在Graviton3和Graviton3E处理器中使用的“Zeus”V1 内核相比,V2 内核的每时钟指令数提高了13%。
显然,这在 IPC中并不是一个大的跳跃,因为核心数量也在跳跃,这就是为什么我们还假设 AWS已经放弃了代工合作伙伴台积电用于蚀刻 Graviton3 和 Graviton3E 芯片的5纳米工艺,而是更密集且有些成熟的4纳米工艺。同样的4N工艺还用于制造 Nvidia 的 Grace CPU 及其“Hopper”GH100 GPU——这两款产品都席卷了生成式 AI 世界。
Graviton4 封装上有 96 个 V2 核心,比 Graviton3 和 Graviton3E 提升了 50%,而且与 8 个 DDR5 内存控制器相比,Graviton4 上有 12 个 DDR5 控制器,并且Graviton4使用的 DDR5内存速度频率提升了16.7%,达到5.6 GHz。通过数学计算,Graviton4 每个插槽的内存带宽为536.7 GB/秒,比之前的Graviton3和Graviton3E处理器提供的307.2 GB/秒高出 75%。
在 Selipsky 的演示以及 AWS 发布的有关 Graviton4 的有限规格中,该公司表示通用 Web 应用程序在 Graviton4 上的运行速度比在 Graviton3 上快 30%(不是 Graviton3E,它超频且很热),但数据库的运行速度将提高 40%,大型 Java 应用程序的运行速度将提高 45%。现在,这可能意味着AWS已经在V2核心中实现了同步多线程 (SMT),为每个核心提供两个线程,就像英特尔和 AMD 的 X86 处理器以及一些 Arm 芯片过去所做的那样。
我们不这么认为,下面的比较显着特征表显示每个套接字有 96 个线程,而不是 192 个线程。我们认为每个套接字有 96 个线程,并且每个核心的二级缓存加倍至2MB对Java和数据库应用程序的性能产生了巨大的影响。您可以通过添加双向SMT获得3倍的vCPU,但这不会为您提供3倍的内存。与 Graviton3 芯片相比,它的内存仍然只有 1.5 倍。
AWS 在其博客中提到的有关使用 Graviton4 芯片的新 R8g 实例的其他内容也让我们犹豫不决:“R8g 实例提供了更大的实例大小,比当前一代 R7g 实例多出 3 倍的 vCPU 和 3 倍的内存。”
R8g 拥有 96 个核心和十几个内存控制器(均比 Graviton3 提升了 1.5 倍),您只会期望 R8g 的 vCPU 数量是使用 Graviton3 芯片的 R7g 实例的 1.5 倍,而内存容量仅是使用 Graviton3 芯片的 R7g 实例的 1.5 倍。因此,我们认为这是 Graviton 系列的第一个双插槽实现。这也是我们认为 Graviton4 芯片拥有大约 9500 万到 1 亿个晶体管的原因之一,而不是您预期的 8250 万个晶体管(如果 AWS 只是在 Graviton3 设计中添加 50% 的核心并保持不变)。我们认为,L2 缓存加倍、增加四个 DDR5 内存控制器以及一对现在也进行线速加密的 I/O 控制器也增加了晶体管预算。
Graviton4在另一个方面也值得注意。过去,Neoverse模块以32核或64核模块完成,Arm建议使用具有UCI-Express或CCIX互连的小芯片来构建更大的处理器复合体。制作自己的 Arm CPU设计的公司总是可以实现单片芯片,出于延迟和功耗的原因,您会这样做。这些互连不是免费的,尤其是具有 96 个内核的芯片,其产量会比 32 个内核或 64 核心低得多。这也是有代价的。
因此,从上面的芯片照片来看,我们认为 Graviton4 是一个双小芯片封装,其中一个小芯片与另一个小芯片旋转了 180 度。这可能就是为什么封装上中央核心复合体左侧和右侧的存储控制器小芯片彼此偏移的原因。
我们认为 Graviton4 与前几代芯片的比较如下:
诚然猜测,我们认为 Graviton4 的性能比 Graviton3E 稍差,但达到该目标所需的功耗却低了近一半,并且内存容量高出 50%,带宽高出 75%,功耗大约为 130 瓦。功率包络具有更低且更理想的 2.7 GHz 时钟速度。
根据我们估计的这些数字(粗体红色斜体显示),Graviton4 芯片的每瓦性能(按 ECU 性能单位测量)与 Graviton3 大致相同,这几乎是您在工艺适度缩减的情况下所希望的一切。
随着更多细节的出现,我们将更新这个故事。
还有一件事:AWS 在其公告中表示(但 Selipsky 并没有在他的主题演讲中吹嘘),迄今为止,它已在其机群中部署了超过 200 万个 Graviton 处理器,并拥有超过 50,000 个客户使用过它们。
这是一个非常可观的 CPU 数量,如果 AWS 没有开始内部生产 Graviton,这些芯片将全部来自 Intel、AMD,甚至可能来自 Ampere Computing。但他们没有。这就是为什么将您的业务计划固定给超大规模提供商和云构建商是一个冒险的提议。
Trainum2旨在云中提供最高性能、最节能的AI模型训练基础设施
此外,AWS还在大会上推出了由 AWS 设计的AWS Trainium2 芯片系列。
Graviton4 和 Trainium2 标志着 AWS 芯片设计的最新创新。随着每一代芯片的推出,AWS 都提供了更好的性价比和能效,除了采用 AMD、Intel 和 NVIDIA 等第三方最新芯片的芯片/实例组合之外,还为客户提供了更多选择,以运行几乎任何应用程序或Amazon Elastic Compute Cloud (Amazon EC2) 上的工作负载。
据了解,Trainium2 的设计速度比第一代 Trainium 芯片快 4 倍,并且能够部署在多达 100,000 个芯片的 EC2 UltraCluster 中,从而可以在一个简单的环境中训练基础模型 (FM) 和大型语言模型 (LLM)。时间的一小部分,同时将能源效率提高了 2 倍。
AWS 计算和网络副总裁 David Brown 表示:“硅支撑着每个客户工作负载,使其成为 AWS 创新的关键领域。” “通过将我们的芯片设计重点放在对客户重要的实际工作负载上,我们能够为他们提供最先进的云基础设施。Graviton4 标志着我们在短短五年内推出的第四代芯片,是我们为各种工作负载打造的最强大、最节能的芯片。随着人们对生成式 AI 兴趣的高涨,Tranium2 将帮助客户以更低的成本和更高的能源效率更快地训练他们的 ML 模型。”
当今新兴的生成式人工智能应用背后的 FM 和 LLM 接受过海量数据集的培训。这些模型使客户能够通过创建各种新内容(包括文本、音频、图像、视频甚至软件代码)来完全重新想象用户体验。当今最先进的 FM 和 LLM 的参数范围从数千亿到数万亿不等,需要可靠的高性能计算能力,能够扩展到数万个机器学习芯片。AWS 已经提供了最广泛、最深入的采用 ML 芯片的 Amazon EC2 实例选择,包括最新的 NVIDIA GPU、Trainium 和 Inferentia2。如今,包括 Databricks、Helixon、Money Forward 和 Amazon Search 团队在内的客户使用 Trainium 来训练大规模深度学习模型,充分利用 Trainium 的高性能、规模、可靠性和低成本。但即使拥有当今最快的加速实例,客户也希望获得更高的性能和规模,以便以更低的成本更快地训练这些日益复杂的模型,同时减少他们使用的能源量。
Trainium2 芯片专为 FM 和 LLM 的高性能训练而设计,参数高达数万亿个。与第一代 Trainium 芯片相比,Trainium2 的训练性能提高了 4 倍,内存容量提高了 3 倍,同时能效(性能/瓦特)提高了 2 倍。Trainium2 将在 Amazon EC2 Trn2 实例中提供,单个实例中包含 16 个 Trainium 芯片。Trn2 实例旨在使客户能够在下一代 EC2 UltraCluster 中扩展多达 100,000 个 Trainium2 芯片,与 AWS Elastic Fabric Adapter (EFA) 拍级网络互连,提供高达 65 exaflops 的计算能力,并为客户提供对超级计算机的按需访问一流的性能。凭借这种规模,客户可以在数周而不是数月内培训 3000 亿个参数的 LLM。通过以显着降低的成本提供最高的横向扩展 ML 训练性能,Trn2 实例可以帮助客户解锁并加速生成 AI 的下一波进步。
一家人工智能安全和研究公司Anthropic表示,“我们正在与 AWS 密切合作,使用 Trainium 芯片开发未来的基础模型。Trainium2 将帮助我们大规模构建和训练模型,对于我们的一些关键工作负载,我们预计它的速度至少比第一代 Trainium 芯片快 4 倍。我们与 AWS 的合作将帮助各种规模的组织释放新的可能性,因为他们将 Anthropic 最先进的人工智能系统与 AWS 安全、可靠的云技术结合使用。”