您当前的位置:检测资讯 > 科研开发
嘉峪检测网 2022-10-06 21:28
制程微缩带来的收益递减,再加上普遍的连通性和数据的指数级增长,行业正在推动芯片设计方式、预期功能以及完成速度的广泛变化。
过去,性能、功率和成本之间的权衡主要由大型 OEM 在行业范围的扩展路线图范围内定义。芯片制造商设计芯片以满足这些 OEM 提出的狭窄规格。但随着摩尔定律的放缓,以及随着越来越多的传感器和电子设备在各处生成更多数据,设计目标和实现这些目标的手段正在发生变化。一些最大的系统公司已经在内部进行芯片设计,以专注于特定的数据类型和用例。与此同时,传统芯片制造商正在创建灵活的架构,这些架构可以重复使用并轻松修改以用于更广泛的应用。
在这种新的设计方案中,需要处理数据的速度和结果的准确性可能会有很大差异。根据具体情况——例如,它是否将用于安全或任务关键型应用,或者它是否靠近可能产生热量或噪音的其他组件——架构师可以权衡原始性能、每瓦性能和总拥有成本,包括可靠性和安全性。这反过来又决定了封装的类型、内存、布局以及需要多少冗余。它还增加了新的关注点,例如跨系统的时钟同步、封装中组件的不同老化率,以及由于行业对各个部分如何组合在一起以及可能出现的问题的了解不足而产生的未知数。
随着这些设计的推出,出现了一些用于定制的创新方法,以及一些一致的主题。
在最近的 Hot Chips 34 大会上,NVIDIA 高级首席工程师 Jack Choquette 预览了该公司新的 800 亿晶体管 GPU 芯片。新架构考虑了空间局部性,允许来自不同位置的数据由可用的处理元素处理,以及时间局部性,其中多个内核可以对数据进行操作。目标是允许更多的块对数据片段进行同步或异步操作,以提高效率和速度。这与现有方法形成对比,在现有方法中,所有线程都必须等待其他数据在处理开始之前到达。
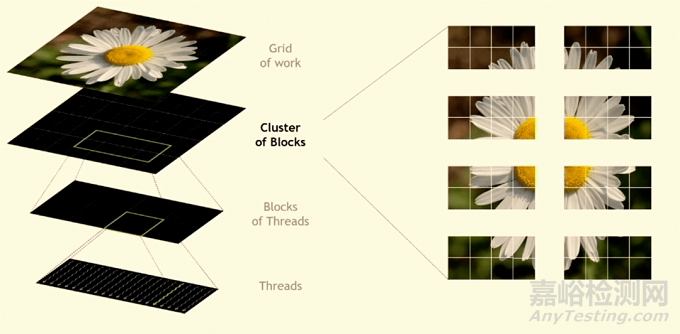
图 1:线程块集群,允许在相邻的多处理器上共同调度一些处理。资料来源:NVIDIA/Hot Chips 34
AMD 高级研究员 Alan Smith 在会议上同样介绍了“workload-optimized compute architecture”。在 AMD 的设计中,为数据转发和重用加宽了数据路径。与 NVIDIA 的架构一样,其目标是消除数据路径的瓶颈、简化操作并提高各种计算元素的利用率。为了提高性能,AMD 不再需要不断复制来备份内存,从而显着减少了数据移动。
AMD 的新 Instinct 芯片包括一个灵活的高速 I/O 和一个连接各种计算元件的 2.5D elevated bridge。High-speed bridges则由英特尔首次通过其嵌入式多芯片互连桥接器 (EMIB) 商业化推出,用于使两个或多个芯片充当一个芯片。Apple 使用了这种方法,桥接了两个基于 Arm 的 M1 SoC 来创建其 M1 Ultra 芯片。
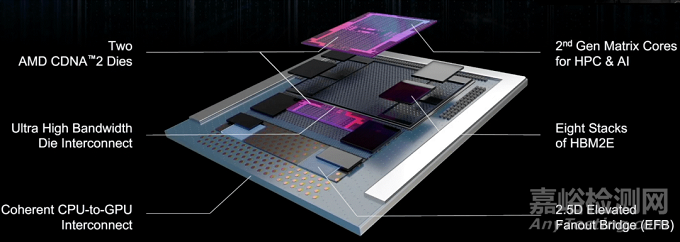
图 2:AMD 的带有扇出桥的多芯片方法。
所有这些架构都比以前的版本更灵活,chiplet/tile 方法为大型芯片制造商提供了一种定制芯片的方式,同时仍为广泛的客户群提供服务。与此同时,谷歌、Meta 和阿里巴巴等系统公司更进一步,从头开始设计芯片,专门针对其数据类型和处理目标进行调整。
特斯拉的数据中心芯片架构就是一个很好的例子。“在人工智能革命的早期阶段,计算需求大致符合摩尔定律,”特斯拉低压和硅工程副总裁Peter Bannon在最近的台积电技术研讨会上发表演讲时说。“但在过去五年中,轨迹发生了明显变化,计算需求每三四个月翻一番,因为人们已经弄清楚如何训练越来越大的模型,从而继续提供越来越好的结果。”
Peter Bannon说,特斯拉设计团队设定了扩大规模的目标,“对机器的尺寸没有实际限制”。“当时的想法是,‘如果机器对于特定型号来说不够大,我们就会把机器做大。’ 我们希望能够利用多个级别的并行性——训练级别的数据和模型级别的并行性,以及训练卷积和矩阵乘法时正在执行的固有操作中的并行性。我们希望它是一个完全可编程且灵活的硬件。”
不同之处
ASIC 一直是定制的,但在每个新的工艺节点,成本都在上升,以至于只有智能手机或 PC 等最大量的应用程序才足以收回设计和制造成本。越来越多的系统公司通过使用他们内部设计的芯片来吸收不断上涨的成本,并且他们希望将这些定制架构扩展到更长的时间。
为了从这些设计中榨取更高的每瓦性能,他们还在针对特定软件功能优化芯片,以及软件如何利用硬件——这是一个复杂且经常迭代的过程,需要通过定期软件更新进行持续微调。例如,在数据中心的情况下,这些芯片可以提高每瓦性能并降低运行温度,从而降低服务器机架供电和冷却的电力成本。
还有其他考虑因素。其中:预计更多设备将作为多芯片或多设备系统的一部分,通常包括 AI/ML 的元素。
为了节省功耗和成本,设计团队根据应用优先考虑不同的功能,然后根据特定的设计目标将多个芯片封装在一起或划分单个 SoC。
随着越来越多的芯片制造商采用小芯片方法,他们需要考虑混合使用关键和非关键数据路径。这涉及从噪声考虑到封装中的芯片移位、由于这些封装中不同材料导致的热膨胀系数以及组件本身的工艺变化等方方面面。尽管 Arm、Synopsys(ARC 处理器)等公司以及越来越多的一些 RISC-V 供应商对他们的 IP 进行了彻底的工作,但极端案例和潜在交互的数量正在增加。
所有这些都使设计、验证和调试过程变得更加困难,并且如果数量和对异常可能出现的位置的了解不足,就会在制造中产生问题。这就解释了为什么越来越多的 EDA、IP、测试/分析和安全公司开始提供服务来补充内部设计团队的工作。
瑞萨电子执行副总裁 Sailesh Chittipeddi 表示:“不再需要设计一个 CPU 来为每个工作负载执行 x、y 和 z 函数,而无需考虑开销。”“这就是为什么所有这些公司现在都变得更加垂直化。他们正在推动他们需要的解决方案。这包括系统级别的人工智能。它包括电气和机械特性之间的相互作用,直至您放置特定连接器的位置。它还推动更多 CAD 公司涉足系统级支持和系统级设计。”
这种转变正在越来越多的垂直市场中发生,从手机和汽车到工业应用,随着芯片制造商希望将其硬件定位于广泛的新市场,它正在推动一波远低于雷达的小型收购浪潮。例如,瑞萨在 6 月收购 Reality Analytics 的目的是为各种工业细分市场创建 AI 模型。
“这项技术可用于观察系统中的振动并预测特定部件何时会发生故障,”Chittipeddi 说。“例如,如果你看看采矿业,如果钻头断裂,可能会导致严重的问题。我们可以将这些模型导入我们的 MCU,用于控制这些系统。”
谁做什么
然而,特定领域的解决方案加大了 EDA 公司的压力,要求他们找出可以自动化的共性。使用在单个工艺节点开发的平面芯片要容易得多。但随着越来越多的市场实现数字化——无论是汽车、工业、军事/航空、商业还是消费者——他们的目标正变得越来越不同。
随着在不同工艺节点开发的小芯片是为定制封装开发的,这种差异预计只会增加,定制封装可能基于从扇出支柱到完整 3D-IC 实现的所有内容。在某些情况下,甚至可能有 2.5D 和 3D-IC 的组合,西门子 EDA 已将其标记为 5.5D。
对于 EDA 和 IP 公司来说,好消息是这显着增加了对仿真、仿真、原型设计和建模的需求。大型系统供应商也一直在向 EDA 供应商施压,以使更多系统公司的设计流程自动化,但没有足够的数量来保证这种投资。取而代之的是,系统公司已经与 EDA 和 IP 公司联系以提供专家服务,从交易关系转变为更深入的合作伙伴关系,并让 EDA 公司更深入地了解各种工具的使用方式以及在哪里使用可以孕育新机会的漏洞。
是德科技副总裁兼设计与仿真部总经理 Niels Faché 表示:“许多新参与者的垂直整合程度更高,因此他们在内部做的更多。”“人们对系统级仿真的兴趣要大得多,而且公司内部和公司之间对协作工作流的需求也在不断增长。我们还看到更多的设计迭代。所以你有一个开发团队,一个质量团队,并且你不断地更新设计。”
对于为 OEM 设计芯片的芯片公司来说,这只是挑战的一部分。“如果你看一下汽车市场,就会发现设计芯片组已经不再是按要求设计了,”Faché 说。“在初始阶段,芯片公司可能会使用该软件构建参考设计,并根据其使用方式进行设置。然后,OEM 将寻求优化。这样做是将合作推向传统的食物链。例如,如果您正在开发雷达芯片,那么它不仅仅是一个雷达子系统。它是更大技术堆栈背景下的雷达。”
该堆栈可能包括射频封装、天线和接收器,而 OEM 使用 EDA 构建无线电。
特定应用与通用
设计团队面临的一个巨大挑战是更多的设计变得前置。不仅仅是创建芯片架构,然后在设计过程中解决细节,更多的问题需要在架构级别解决。
Siemens Digital Industries Software执行副总裁 Joe Sawicki 表示:“曾经有一次芯片公司出货的芯片耗电量过多,而 OEM 对此并不满意。”“但你不会知道仅仅运行应用程序。人工智能使这个问题变得更大,因为它不仅仅是软件的问题。现在,您可以在其上运行所有这些推理。如果您不关心延迟,您可以在云中放置一个通用芯片,您只需与云通信并取回数据即可。但是,如果你有实时的东西,它需要立即响应,你就无法承受这种延迟并且你想要低功耗。所以,至少对于加速器,你想要定制设计。”
Synopsys的产品营销经理 Gordon Cooper表示同意。“如果你在使用人工智能,是 100% 的时间都在使用它,还是很高兴拥有它?如果我只想说我的芯片上有人工智能,也许我只需要使用 DSP 来做人工智能,”他说。“有一个权衡,这取决于上下文。如果你想要 100% 的时间完全成熟的 AI,也许你需要添加外部 IP 或额外的 IP。”
人工智能面临的一大挑战是让设备保持最新状态,因为算法会不断更新。如果设计是一次性的并且所有内容都针对一种或多种算法进行了优化,这将变得更加困难。因此,虽然架构需要在性能方面具有可扩展性,但它们也需要随着时间的推移以及系统中其他组件的上下文而具有可扩展性。
软件更新会对时钟造成严重破坏。Movellus首席执行官 Mo Faisal在 2022 年人工智能硬件峰会上的一次演讲中表示:“你对芯片同步质量所做的任何事情都会影响延迟、性能、功耗和上市时间。”越来越大的芯片 - 标线大小的芯片 - 您可以优化内核并确保它与软件很好地配合。这是矩阵乘法、图形计算,你并行投入的核心越多越好。然而,这些芯片现在正面临挑战。以前,这对英特尔和 AMD 的一两个团队来说是个问题,现在这是每个人的问题。”
保持一切同步正在成为一个过程,而不是一个单一的功能。“你可能有不同的工作量,”Faisal说。“因此,您可能只想为一个工作负载使用 50 个内核,而对于下一个工作负载,您希望使用 500 个内核。但是当你打开接下来的 500 个内核时,你最终会给电网施加压力并导致下降。”
同时开关噪声也存在问题。在过去,其中一些问题可以通过冗余来解决。但在先进节点上,该裕量增加了将电子移动通过非常细的导线所需的时间和能量,这反过来又会产生电阻并增加热耗散。因此,每个新节点的权衡变得更加复杂,并且包中不同组件之间的交互是相加的。
“如果你看一下 5G,这对汽车来说意味着与数据中心或消费者不同的东西,” Cadence产品营销集团总监 Frank Schirrmeister在接受采访时说。“它们都有不同的延迟吞吐量。人工智能/机器学习也是如此。这取决于域。然后,因为一切都是超连接的,它不仅在一个域内。所以它本质上需要同一芯片的许多变体,这就是异构集成变得有趣的地方。SoC 的整体解体派上用场了,因为您可以根据 binning 之类的内容执行不同的性能级别。但它本身不再是一种设计,因为某些规则不再适用。”
结论
整个芯片设计生态系统都在不断变化,并且一直延伸到软件。过去,设计团队可以确保以高抽象级别编写的软件可以运行良好,并且在每个新节点的引入都会有定期的改进。但是随着规模下降的好处以及随后需要更快处理的数据的增加,现在每个人都必须更加努力地工作——他们必须与他们在过去的。
至少就功耗和性能而言,最好的前进方式是使用定制或半定制架构为特定目的设计芯片。但这会产生一系列问题,而这些问题需要时间来解决。用于 2.5D 和 3D 设计的工具刚刚开始推出,芯片制造商正在整理计划,以使它们变得非常具体,或者足够通用,以便能够在多个设计中利用其架构。无论哪种方式,每个学科的工程师都需要开始超越他们的关注领域,转向芯片系统和系统系统。
未来是光明的,但也更具挑战性。

来源:半导体行业观察


