您当前的位置:检测资讯 > 科研开发
嘉峪检测网 2021-07-20 21:56
相信点开这篇文章的读者,一定或多或少接触过“高可靠”“高可用”这些字眼,但是往往或语焉不详,或罗列术语(MTBF、MTTR ...),那么我们到底应该如何定量描述系统的可靠性和可用性指标呢,这些看着很上流的术语到底意味着什么呢?
首先了解一下故障的定义:
故障定义
硬件故障(Hardware failure)
工业界通常使用“浴盆曲线”来描述硬件故障,具体如下图所示。具体来说,硬件的生命周期一般被划分为三个时期:
1) The first part is a decreasing failure rate, known as early failures
2) The second part is a constant failure rate, known as random failures
3) The third part is an increasing failure rate, known as wear-out failures

图1. 浴盆曲线(Bath tubcurve)
软件故障(Software failure)
软件故障可以通过每千行代码的缺陷数(Defects/KLOC)进行测量,称为缺陷密度(Defect Density):
Defect Density= Number of Defects / KLOC
影响缺陷密度的因素主要有如下几点:
1)软件过程(代码评审、单元测试等)
2)软件复杂度
3)软件规模
4)开发团队经验
5)可复用代码比例(久经考验的代码)
6)产品交付前的测试
衡量指标
平均故障间隔时间(MTBF)
英文全称:Mean Time Between Failure,顾名思义,是指相邻两次故障之间的平均工作时间,是衡量一个产品的可靠性指标。
故障率(Failure Rate)
以下文字摘自wiki,避免翻译失真:
Failure rate is the frequency with which an engineered system or component fails,expressed, for example, in failures per hour. It is often denoted by the Greekletter λ (lambda) and is important in reliability engineering.
The failure rate of a system usually depends on time, with the rate varying overthe life cycle of the system. For example, an automobile's failure rate in itsfifth year of service may be many times greater than its failure rate duringits first year of service. One does not expect to replace an exhaust pipe,overhaul the brakes, or have major transmission problems in a new vehicle.
In practice, the mean time between failures (MTBF, 1/λ) is often reported insteadof the failure rate. This is valid and useful if the failure rate may beassumed constant – often used for complex units / systems, electronics – and isa general agreement in some reliability standards (Military and Aerospace). Itdoes in this case only relate to the flat region of the bathtub curve, alsocalled the "useful life period". Because of this, it is incorrect to extrapolateMTBF to give an estimate of the service life time of a component, which willtypically be much less than suggested by the MTBF due to the much higher failurerates in the "end-of-life wear out" part of the" bathtubcurve".
为便于理解,举个例子:比如正在运行中的100只硬盘,1年之内出了2次故障,则故障率为0.02次/年。
上文提到的关于MTBF和Failure Rate关系值得细细体会,在现实生活中,硬件厂商也的确更热衷于在产品上标注MTBF(个人猜测是因为MTBF往往高达十万小时甚至百万小时,容易吸引眼球)。Failure Rate伴随着产品生命周期会产生变化,因此,只有在前述“浴盆曲线”的平坦底部(通俗点说就是产品的“青壮年时期”)才存在如下关系:
MTBF= 1/λ
平均修复时间(MTTR)
英文全称:Mean Time To Repair,顾名思义,是描述产品由故障状态转为工作状态时修理时间的平均值。在工程学,MTTR是衡量产品维修性的值,在维护合约里很常见,并以之作为服务收费的准则。

图2. 硬件MTTR估算

图3. 软件MTTR估算
可用性(Availability)
GB/T3187-97对可用性的定义:在要求的外部资源得到保证的前提下,产品在规定的条件下和规定的时刻或时间区间内处于可执行规定功能状态的能力。它是产品可靠性、维修性和维修保障性的综合反映。

关于Availability这个计算公式,很容易理解,这里不多做解释。通常大家习惯用N个9来表征系统可用性,比如99.9%(3-ninesavailability),99.999%(5-ninesavailability)。
宕机时间(Downtime)
顾名思义,指机器出现故障的停机时间。这里之所以会提Downtime,是因为使用每年的宕机时间来衡量系统可用性,更符合直觉,更容易理解。
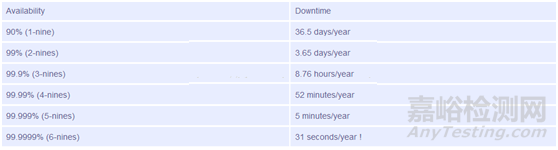
图4. Availability与Downtime对应关系
延伸思考
MTBF不靠谱?
一般来说,服务器的主要部件MTBF,厂商标称值都在百万小时以上。比如:主板、CPU、硬盘为100wh,内存为400wh(4根内存约为100wh),从而可以推算出服务器整体MTBF约25wh(约30年),年故障约3%,也就是说,100台服务器每年总要坏那么几台。
上面的理论计算看着貌似也没啥问题,感觉还挺靠谱。但如果换个角度想想,总觉得哪里不太对劲:MTBF约30年,难道说可以期望它服役30年?先看看**的工程师如何解释:
It is common to see MTBF ratings between 300,000 to 1,200,000 hours for hard disk drivemechanisms, which might lead one to conclude that the specification promisesbetween 30 and 120 years of continuous operation. This is not the case! Thespecification is based on a large (statistically significant) number of drivesrunning continuously at a test site, with data extrapolated according tovarious known statistical models to yield the results.
Based on the observed error rate over a few weeks or months, the MTBF is estimatedand not representative of how long your individual drive, or any individualproduct, is likely to last. Nor isthe MTBF a warranty - it is representative ofthe relative reliability of a family of products. A higher MTBF merely suggestsa generally more reliable and robust family of mechanisms (depending upon theconsistency of the statistical models used). Historically, the field MTBF, whichincludes all returns regardless of cause, is typically 50-60% of projected MTBF.
看到这里,再联系前文对于Failure Rate的阐述,我知道各位读者有没有摸清其中的门道。其实说白了很简单,这些厂商真正测算的是产品在“青壮年”健康时期的Failure Rate,然后基于与MTBF的倒数关系,得出了动辄百万小时的MTBF。而现实世界中,这些产品的Failure Rate在“中晚年”时期会快速上升,因此,这些MTBF根本无法反映产品的真实寿命。文中也提到,**也意识到MTBF存在弊端,因此改用AFR(AnnualizedFailure Rate),俗称“年度不良率”。
其实,早在2007年,Google和CMU同时在FAST07发表论文,详细讨论了硬盘故障的问题:
CMU《Diskfailures in the real world: What does an MTTF of 1,000,000 hours mean to you?》
Google《FailureTrends in a Large Disk Drive Population》
Google采集了公司超过10w块消费级HDD硬盘数据(SATA和PATA,5400转和7200转,7家不同厂商,9种不同型号,容量从80G到400G不等),最终得出如下数据:
Google found that disks had an annualized failure rate (AFR) of 3% for the first threemonths, dropping to 2% for the first year. In the second year the AFR climbed to8% and stayed in the 6% to 9% range for years 3-5.

来源:Internet


