您当前的位置:检测资讯 > 科研开发
嘉峪检测网 2021-06-04 12:16
一、引言
近年,国内可靠性领域的蓬勃发展,最近“祝融登火” (一系列各种功能的分子系统,经历了发射阶段的高加速度、高强振动,太空飞行阶段的超高低温、强辐射等极端恶劣环境后登陆火星)成功,就是可靠性发展最好的诠释,其中凝聚了可靠性人的辛劳与汗水,这些可靠性人都是可靠性工作者中的佼佼者,值得大家仰慕。
然而,不可否认的事实是,可靠性工作但仍集中于军工,研究所,少部分大企业。绝大部分中小企业因可靠性的较大投入而却步;另一些大企业会因可靠性效果的不确定性与见效慢,而认为可靠性是鸡肋。从宏观讲,以上种种导致国内可靠性的发展不温不火;在可靠性工作实施过程中,尤其是在企业推行可靠性时,一些对可靠性的误解,让可靠性变得“不可靠”,让可靠性人哭笑不得,极为尴尬。本文主要从以下几个方面来进行介绍浅谈。
二、缺少时间参数的可靠度
说起可靠性,会经常被谈论“可靠度”指标。比如“听说XX公司XX产品的可靠度是0.9,那我们公司的产品的可靠度是多少”之类。相信大多数可靠性人不会正面回答该问题,而是从可靠度的定义“产品在规定的条件下和规定的时间内,完成规定功能的概率”来解释可靠度函数R(t)是一个时间参数的函数。脱离时间参数讲可靠度,就是拿不同的量具量测不同的事物,量测出的结果也就毫无意义,即便时间参数相同,不同的产品类型,可靠度值的大小也不应被拿出来对比。
三、让人抓狂的寿命指标
介绍以下几个寿命指标的简要定义:
a.平均寿命Mean Life:产品寿命的平均值;
b.中位寿命Median Life:产品寿命排序后的中位值;
c. MTBF:平均故障间隔时间;
d. MTTF:平均失效前时间;
e.特征寿命:Weibull函数的尺寸参数η
f. Bx寿命:累积达到x%的产品失效的时间点。
相信刚接触这些寿命概念的人,一定会混淆,一旦被人追问,就会抓狂。
在此简单总结以下这几个寿命指标的差异分别见表一:
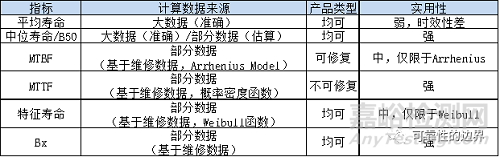
表一
某案例分析中出现的几种寿命指标,见图一:
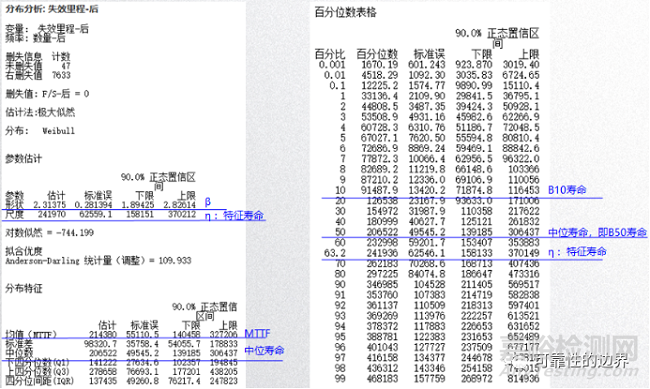
综上,不同的方式计算出的寿命指标不具备比较性,即如果衡量某产品不同阶段的寿命,必须采用相同的计算方式,相同的寿命指标才能横纵向对比。
四、条件可靠度R(T,t)预估返修数的漂移
条件可靠度R(T,t):工作到某时刻T时尚未失效的产品,在该时刻T之后的某段时间t内不发生失效的概率。
相信很多企业领导在接触条件可靠度后,会要求可靠性人对企业产品的返修数进行预估。于是乎,可靠性人经过返修数据收集,统计分析,失效概率分布,条件可靠度推算后,得出一串的预估的返修数,甚至都加上90%的正态置信区间,而且还反推出最近一次的实际返修数在预估返修数的置信区间内。到此,本以为干了一件很“漂亮”的活,可是随着t的增大,多数人会发现实际返修数在逐步从置信区间内漂移到置信区间外,可靠性人的心开始变得“哇凉哇凉”。这是为什么呢?
梳理一下R(T,t)的计算公式:

从统计学角度,在此公式中,已知返修数据的失效分布函数需服从weibull概率密度函数,那么问题来了,如何判定失效分布服从weibull分布?而实际返修数据为右删失数据,无法采用检定的方式进行判定,通常有两种处理方式:
一是直接假定服从weibull分布。该方式可以保证每次都用相同的计算方式和相同的寿命指标。示例见图二:
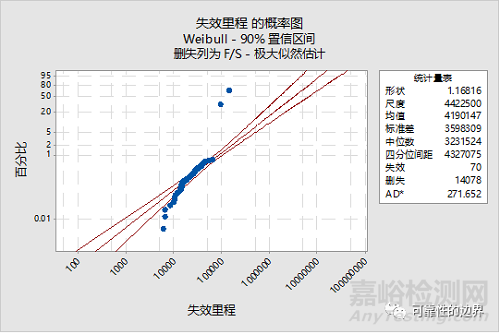
图二
二是采用分布ID图极大似然估计进行分布评估,通常选择AD值较小的分布函数。该方式可以保证已有的数据拟合度较高,但当数据更新后,每次选择的分布函数不一定相同。示例见图三、图四:
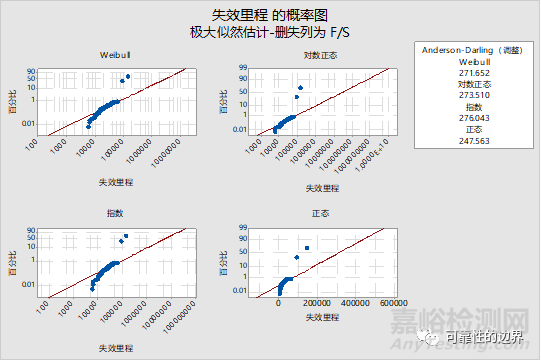
图三
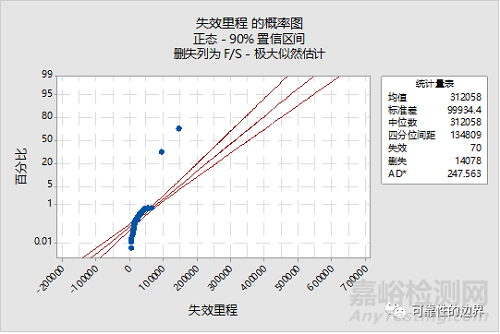
图四
综上,无论选择哪一种方式,都无法保证失效分布严格服从weibull(或其它)分布,就会导致出现预估“失败”。如图四中,正态分布已是AD值最小的分布函数,但可以看出,随着时间轴向右推移,曲线必然漂移出置信区间。
为什么会出现失效分布不符合分布函数呢?其实对于单一失效模式,且数据是全数据时,通常都服从某种分布函数。而实际产品,通常有多种失效模式,当无法有效将多种失效模式识别区分开,多个分布函数的数据叠加后,就不再服从任何分布函数了。也就是,产品系统越复杂,条件可靠度漂移越严重。
五、可靠性预计工作的尴尬
以下内容摘录自北航康锐教授的文章《标准陈旧|从[祝融]成功登陆火星,看可靠性预计工作的尴尬》。
现行的常规做法,选用20世纪90年代发布的美国军用标准217F和2006年发布的中国军用标准299C。按照这些标准中的预计模型,计算[祝融]的失效率的步骤是:先从标准中查到每一类元器件的失效率,根据制造和使用条件,选择对应的修正因子,得到每个元器件的失效率,再将所有元器件的失效率进行相加,得到整机的失效率。然而组成[祝融]的零件应该数以百万计,经过相加后,[祝融]的失效率必定高到让自己都怀疑人生,无法回应领导和客户的质疑。
这种令人难以置信的预计结果几乎没人会相信,丧失专业权威性,被决策者直接跳过或者忽略,这也是可靠性人的噩梦。
造成这个结果的原因:
一是标准陈旧,很多元器件的技术不断进步,标准中的失效率和修正因子已不适用;而且还有很多新元器件在标准中找不到预计模型;
二是标准中采用元器件失效率直接相加的算法不科学。这样的算法的底层数学逻辑是概率乘积定理,而该定理使用的前提:是独立事件的发生概率相乘。工程实践中,这样的假设是不存在的,各种元器件相互关联,也是失效相联,这种联系对产品整体失效率的影响,直接被元器件失效率的“加和”算法无视了。
以上林林总总,有的需要可靠性人耐心的讲解可靠性词汇的定义和差异;有的是因为信息的不明确及模型适用性受限,导致无法得出“有效”的结果;还有的是可靠性技术发展受限,导致可靠性结论失真,导致工作成果遭到忽略。
国内企业的发展,首先考虑的是生存问题,其次是盈利问题,再其次才是质量可靠性造成的品牌问题,加之可靠性的“不可靠”,导致可靠性工作大多被边缘化,生存土壤劣化,严重制约国内可靠性的发展。
随着国内经济、技术不断发展,越来越多的企业已经进入行业前沿,基本无需考虑生存问题和盈利问题,此时可靠性问题逐步浮出水面。但可靠性的发展并不可一蹴而就,需要积累深耕。越来越多的前沿企业已经意识到这种趋势,开始开展可靠性活动,也希望他们能了解可靠性的“不可靠”,能在工作中给予更多的支持和包容,让可靠性人能更充分,更安心的开展工作,让企业可靠性更上一层楼,跻身为行业领跑者。

来源:可靠性的边界/王进


