您当前的位置:检测资讯 > 科研开发
嘉峪检测网 2024-12-24 10:50
在 IEDM 上,人们对即将转向全栅 (GAA) 晶体管结构进行了大量讨论。这种新设备为继续缩小设备尺寸带来了许多好处,无论是在单片设备级别还是在多芯片设计中。通往 GAA 的道路并不简单,需要处理新的材料、工艺和设计考虑因素。台积电在这方面投入了大量精力。
其中,Geoffrey Yeap 博士于周一在 IEDM 上展示了2nm 平台技术,该技术采用节能纳米片晶体管和互连,并与 3DIC 共同优化,适用于 AI、HPC 和移动 SoC 应用。他是台积电先进技术研发副总裁。Geoffrey 在台积电工作了近九年,还曾领导高通、摩托罗拉移动、AMD 和德克萨斯大学超级计算系统中心的先进工作。
正如标题所说,这项工作专注于尖端的 2nm CMOS 平台技术 (N2),该技术是为 AI、移动和 HPC 应用中的节能计算而开发和设计的。Geoffrey 解释说,自 2023 年第一季度生成式 AI 取得突破以来,AI 与 5G 先进移动和 HPC 一起在半导体行业中引发了对一流节能逻辑技术的巨大需求,这项工作满足了这一需求。
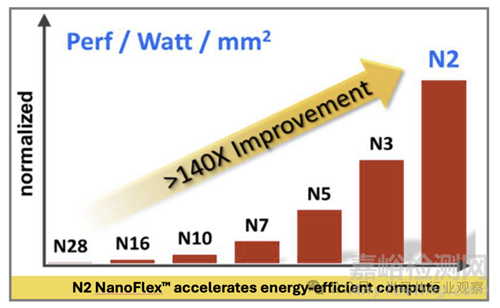
Geoffrey 介绍了最先进的台积电 N2 技术及其成功过渡到 NS 平台技术的过程,从 28nm 到 N2,计算能效提升了 140 倍以上,如上面图表所示。N2 逻辑技术采用节能的全栅极纳米片晶体管、中线和后端互连,以及最密集的 SRAM 宏约 38Mb/mm2。N2 提供了比之前的 3nm 节点更佳的节点优势,速度提升了 15%,功耗降低了 30%,芯片密度提高了 1.15 倍以上。
N2 平台技术配备了新的铜可扩展 RDL 互连、平面钝化和 TSV。它与台积电的 3DFabric技术进行了整体优化,实现了目标 AI/移动/HPC 产品设计的系统集成/扩展。
Geoffrey 报告称,N2 已成功满足晶圆级可靠性要求,并通过了 1,000 小时的 HTOL 认证,具有高良率 256Mb HC/HD SRAM 和由 CPU/GPU/SoC 块组成的逻辑测试芯片(>3B 门)。N2 目前处于风险生产阶段。N2 平台技术计划于 2025 年下半年实现量产。N2P 是 N2 的 5% 速度增强版,具有完全的 GDS 兼容性,目标是在 2025 年完成认证,并于 2026 年实现量产。
从平台角度来看,Geoffrey 提供了有关 N2 NanoFlex技术架构的一些细节。系统技术协同优化 (STCO) 与智能缩放功能相结合,而不是蛮力设计规则缩放,后者会大幅增加工艺成本并无意中导致关键产量问题。在优化技术以实现目标 PPA 的过程中,进行了广泛的 STCO 以及主要设计规则(例如栅极、纳米片、MoL、Cu RDL、钝化、TSV)的智能缩放。
他指出,通过与 3DFabric SoIC 3D 堆叠和先进封装技术 (INFO/CoWoS 变体) 进行协同优化,加速了 AI/移动/HPC 产品设计的系统集成/扩展。N2 NanoFlex 标准单元创新不仅提供纳米片宽度调制,还提供多单元架构所期望的设计灵活性。
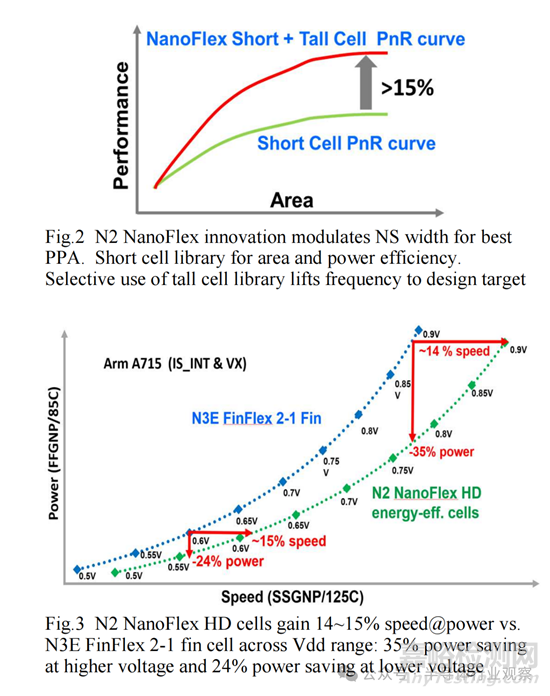
此功能为 N2 提供了短单元库,以节省面积和功耗。他解释说,选择性使用高单元库元素可以提高频率以满足设计目标。凭借 6 个 Vt 产品,跨越 200mV,N2 提供了前所未有的设计灵活性,可以以最佳逻辑密度满足各种节能计算应用。下图说明了这种方法对基于 Arm 的设计的一些好处。
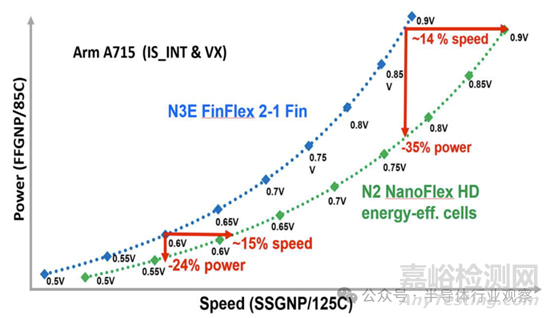
Geoffrey 解释说,在 0.5V-0.6V 的低 Vdd 范围内,N2 纳米片技术的性能/瓦特比 FinFET 好得多。通过工艺和设备的持续改进,重点放在低 Vdd 性能/瓦特的提升上,从而在 0.5V 操作下将速度提高 20%,待机功耗降低 75%。N2 NanoFlex 与多 Vt 相结合,提供了前所未有的设计灵活性,以最具竞争力的逻辑密度满足各种节能计算应用的需求。
Geoffrey 详细介绍了 SRAM、逻辑测试芯片以及认证和可靠性。这是一次令人印象深刻的演示。N2 技术平台为未来的创新带来了许多新功能。
以下为题为《2nm Platform Technology featuring Energy-efficient Nanosheet Transistors and Interconnects co-optimized with 3DIC for AI, HPC and Mobile SoC Applications》的原文翻译
摘要
一种先进的 2nm CMOS 平台技术 (N2) 已开发并设计用于 AI、移动和 HPC 应用中的节能计算。这种业界领先的 N2 逻辑技术具有节能的全栅极纳米片晶体管、中线和后端互连以及最密集的 SRAM 宏 ~38Mb/mm2。
N2 提供了比之前的 3nm 节点 更完整的节点优势,速度提高了 15% 或功耗降低了 30%,芯片密度提高了 1.15 倍以上。N2 平台技术配备了新的 Cu 可扩展 RDL、平面钝化和 TSV,与 3DFabricTM 技术一起进行了整体优化,从而实现了 AI/移动/HPC 产品设计的系统集成/扩展。
N2 成功满足了晶圆级可靠性要求,并通过了 1000 小时 HTOL 鉴定,具有高良率 256Mb HC/HD SRAM 和由 CPU/GPU/SoC 块组成的逻辑测试芯片(>3B 门)。目前处于风险生产阶段,N2 平台技术计划于 2025 年下半年量产。N2P 是 N2 的 5% 速度增强版,具有完全的 GDS 兼容性,目标是在 2025 年完成鉴定,并在 2026 年量产。
简介
先进的 CMOS 技术一直是半导体产品创新的关键推动因素。自 2023 年第一季度人工智能取得突破以来,人工智能与 5G 先进移动和 HPC 一起点燃了行业对一流先进节能逻辑技术的无限渴求。
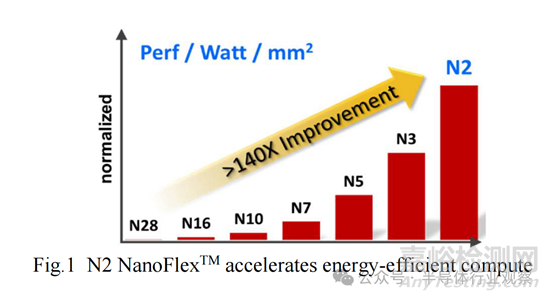
我们业界领先的 2nm 平台技术 (N2) 就是这样一种先进的逻辑技术。本文介绍了最先进的 N2 技术成功过渡到 NS 平台技术的过程,以及从 28nm 到 N2 的 >140 倍节能计算加速,如图 1 所示。我们还介绍了系统技术协同优化 (STCO) 创新,包括设计规则、标准单元、SRAM 和与 3DFabricTM 的互连协同优化。N2 技术已在我们的开发/质量test vehicle上得到验证。N2 满足所有晶圆级可靠性要求,并完成了完整的 1000 小时 HTOL 认证,具有高良率 256Mb HD/HC SRAM 和逻辑测试芯片(>3B 门)。
目前,N2 已进入风险生产阶段,有望在 2025 年下半年实现量产。N2P 的速度提高了 5%,并具有完整的 GDS 兼容性,目标是在 2025 年完成认证,并在 2026 年实现量产。
N2 NanoFlex 技术架构
N2 2nm 平台技术的定义和开发旨在满足 PPACt(功率、性能、面积、成本和上市时间)。STCO 强调智能缩放功能,而不是蛮力设计规则缩放,后者会大幅增加工艺成本并无意中导致关键产量问题。在优化这项 2nm 技术以实现目标 PPA 时,进行了广泛的 STCO 以及主要设计规则(例如栅极、纳米片、MoL、Cu RDL、钝化、TSV)的智能缩放。这项开发还涉及与 3DFabricTM SoIC 3D 堆叠和先进封装技术(INFO/CoWoS 变体)的共同优化,从而加速 AI/移动/HPC 产品设计的系统集成/扩展。
N2 NanoFlex标准单元创新不仅提供了纳米片宽度调制,还提供了多单元架构所期望的设计灵活性。N2 短单元库可实现面积和功率效率。选择性使用高单元库可提升频率以满足设计目标。结合跨越 200mV 的六伏特产品,N2 可提供前所未有的设计灵活性,以最佳逻辑密度满足各种节能计算应用。N2 以预计的成本和上市时间提供具有吸引力 PPA 值的全节点扩展:速度提升约 15% 或功耗降低约 30%,芯片密度扩展 >1.15 倍(图 2-3)。
节能纳米片晶体管、MoL 和 BEOL 互连
从 16nm 到 7nm(2-fin)节点,使用了多代具有鳍片减少功能的 Si FinFet。高迁移率通道晶体管采用业界首创的零厚度偶极子真多 Vt(7-Vt)、切割金属栅极和栅极接触过度激活创新,将 FinFet 架构扩展到 N5 节点。

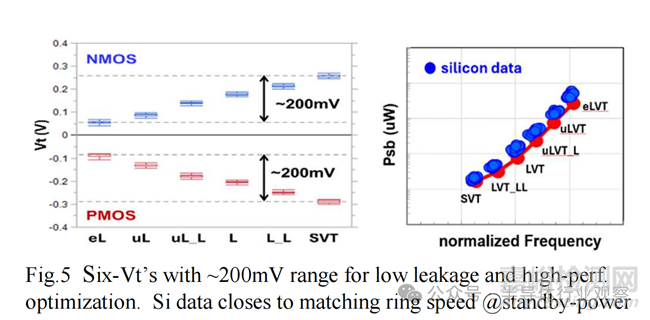
FinFlex DTCO 与其他关键增强功能相结合,在最后一个 FinFet 节点 N3 中成功提取了另一个全节点 PPA 优势 。N2 平台技术成功完成了从 FinFet 到节能纳米片技术的过渡。图 4 显示了优化的标称栅极长度 NS 晶体管,具有出色的 DIBL 和子阈值摆幅。长栅极长度 NS 晶体管实现接近理想的 60.1mV/dec 摆幅。图 5 显示了 N2 N/P FET 的 6 个 Vt,范围从极低 Vt 到标准 Vt,跨度约为 200mV。Si 数据非常接近匹配所有六个 Vt 下的环速度待机功率(speed@standby-power)。
这种多 Vt 功能是通过第三代(自 N5 以来)基于偶极子的多 Vt 集成实现的,该集成包括 n 型和 p 型偶极子。
许多工艺和设备改进不仅侧重于通过薄片界面/厚度、结工程、掺杂剂扩散/激活和应力工程来设计晶体管驱动电流,而且侧重于降低 Ceff,以实现一流的能效。
所有这些改进使 NS N/P FET 的 I/CV 速度分别提高了 70% 和 110%。N2 纳米片技术在 0.5V-0.6V 的低 Vdd 范围内表现出比 FinFET 更好的性能/瓦特(图 7)。重点是通过工艺和设备的持续改进来提高低 Vdd Perf/Watt,从而在 0.5V 操作下实现 20% 的速度增益和 75% 的待机功耗降低。N2 NanoFlex 与多 Vt 相结合,提供了前所未有的设计灵活性,可以满足最具竞争力的逻辑密度下广泛的节能计算应用。

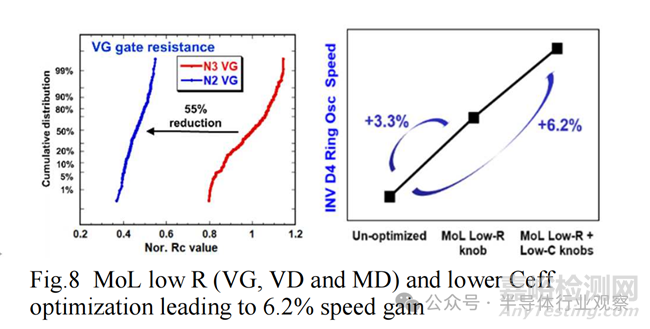
整体技术能效和性能也严重依赖于 MoL、后端和远后端互连。凭借创新的材料和工艺,无障碍全钨 MoL 可将 VG Rc 显着降低 55%。低电阻 MoL 与电容减小功能相结合,可实现总计约 6.2% 的 INV D4 环形振荡器速度增益(图 8)。
采用新颖的 1P1E EUV 图案化优化的 M1 可将标准单元电容减少近 10%,并节省多个 EUV 掩模。在最紧密的 193i 1P1E 工作室金属/通孔层上可以看到 My RC 和 Vy Rc 的大幅减少(图 12)。总之,N2 MoL 和 BEOL RC 减少了 ~>20%,对节能计算做出了重大贡献。
与 3DFabric 技术的无缝集成
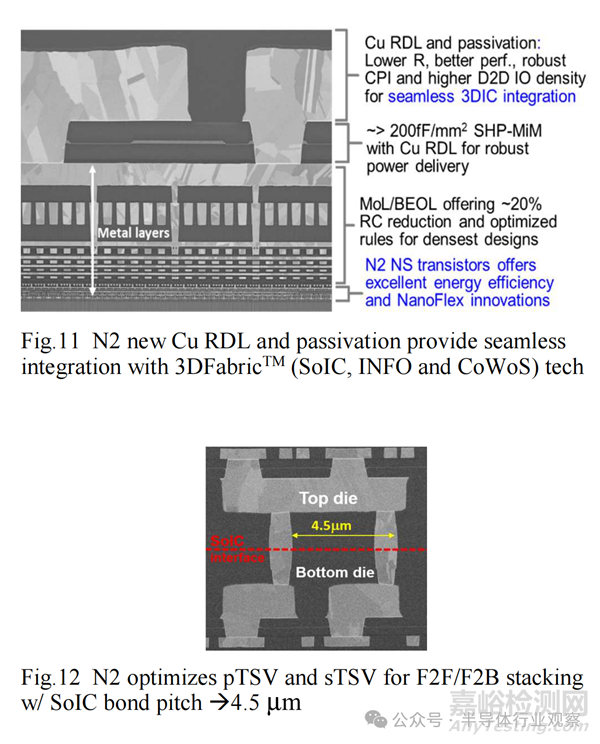
这项 2nm 平台技术包括具有平面钝化(flat passivation)和 TSV 的新 Cu RDL,与 3DIC 共同进行整体优化,从而实现 AI/移动/HPC 产品设计的系统集成/扩展(图 11-12)。我们注重优化后端/远后端的材料和工艺,以实现全局翘曲和局部平面性,从而与 3D 堆叠实现稳健集成。N2 还优化了 pTSV/sTSV(用于电源/信号),使其具有 F2F/F2B 堆叠的 CD/间距/密度,SoIC 键间距从 9µm/6µm 缩小到 4.5µm。
SRAM、逻辑测试芯片和质量/可靠性
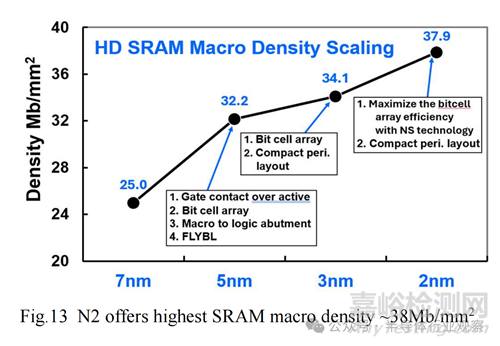
对于高级节点,SRAM 位单元缩放已成为一项挑战。借助 N2 NanoFlex 和改进的开关电流,采用 DTCO 来最大化 #bitcell/bitline、位线加载和 SRAM 外围设备布局效率,从而实现最密集的 2nm SRAM 宏密度~38Mbmm2(图 13)。
N2 HC/HD 下拉 Nfet 的 Vt-sigma 优于 FinFet,导致 HC Vmin 降低 ~20mV,HD Vmin 降低 30~35mV(图 14)。图 15 中的 HD 256Mb SRAM shmoo 图说明了完全读取和写入至 ~0.4V。凭借创新的阱设计和结隔离,N2 的逻辑和 SRAM 闩锁触发电压均优于 FinFet(图 15)。

N2 中更高的 Vtrig 可提高逻辑密度,并可更有效地进行 DVS 产品质量筛选。N2 测试芯片展示了健康的 CPU/GPU 功能,并通过了图 16 所示的 GPU Vmin 功率规格。N2 256Mb HC/HDSRAM 始终表现出健康的缺陷密度,平均/峰值良率 >80% / >90%(无维修)。
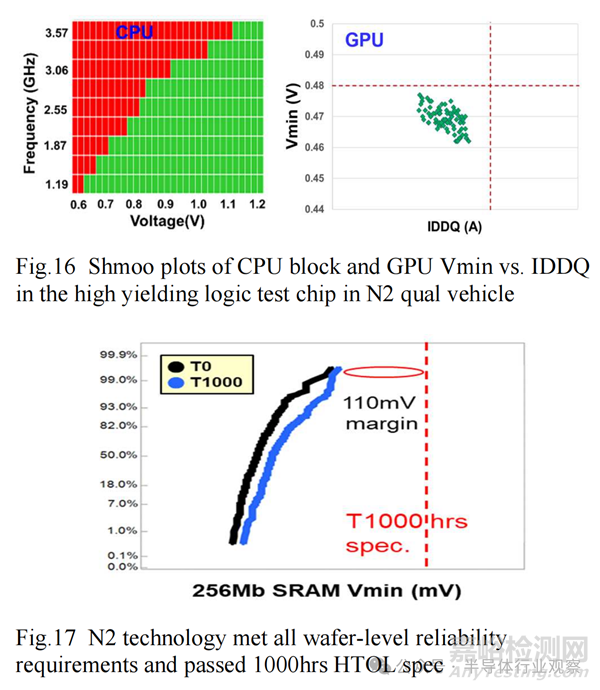
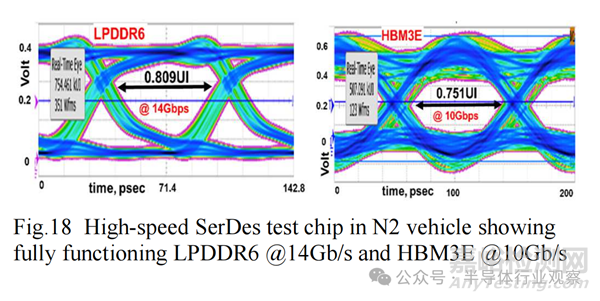
图 20 显示 256Mb SRAM 通过了 1000 小时 HTOL 认证,裕度约为 110mV。通过最小化瞬态电压下降,可提供额外的 HPC 功能,例如超高性能 MiM (SHP-MiM),电容密度约为 200fF/mm²,以实现更高的 Fmax。高速 SerDes 测试芯片还演示了功能齐全的 14Gb/s LPDDR6 和 10Gb/s HBM3E 接口。

来源:Internet


