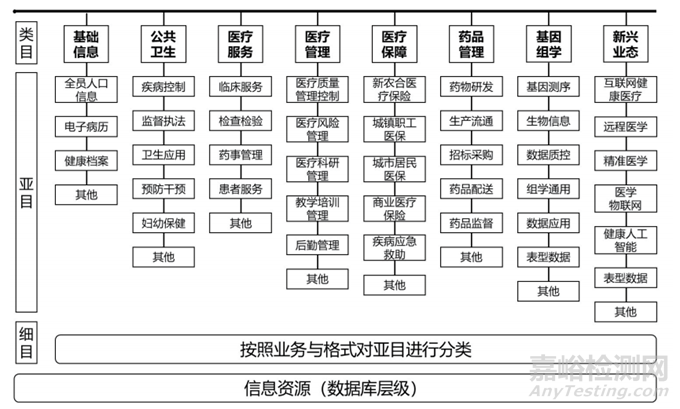
健康医疗领域的大数据用户覆盖范围广,包括临床医生和科研人员、医疗卫生管理部门及公共卫生机构工作人员,以及第三方企业用户和社会大众等。相应的数据资源分散在不同单位、不同信息系统的数据池中,包括医院的电子病历、结算与费用数据和各业务系统数据等,医疗厂商的医药、医械数据等,这些数据结构各异且彼此之间联系紧密。见图1。
图1 健康医疗大数据分类
医院内部数据是健康医疗大数据平台的主要数据来源,由于医院内部的信息系统较多,涉及不同厂商、不同业务范围(主要包括临床诊疗、临床支持、运营管理等方面),存在医院管理信息系统(hospitalmanagementinformationsystem,HMIS)、电子病历系统、影像归档和通信系统(picturearchivingandcommunicationsystem,PACS)、科研系统等,信息集成相对薄弱。例如,对院内异构系统以传统点对点接口方式进行对接,信息集成范围和集成效果不理想,存在信息孤岛和数据同步方面的问题。仅有少数医院建立了集成平台和数据中心,但跨机构间共享程度依旧不足。
此外,医院内部信息系统相对独立,虽然在长期服务过程中积累了大量的医疗数据,部分医疗机构完成了数据集成工作,但所收集的数据依然存在标准不一、存储格式各异等问题,未能汇聚成规范统一的健康医疗大数据资源,难以有效地管理和利用。各个医疗机构之间信息系统很少有对接,数据汇聚和共享利用率低。
医学人工智能应用有限且知识利用不足
健康医疗大数据的价值在于高效利用数据为相关工作提供决策支持和数据服务。目前有大量的临床数据为非结构化自由录入文书,例如患者的手术记录、诊断报告等,其中蕴藏大量有价值的信息。但是自由文本信息往往具有多模态、多源的特点,再加上受汉字歧义性和原始信息结构不完整等因素影响,现有数据挖掘和知识加工技术难以满足健康医疗大数据的人工智能应用需求,也缺乏高效算法和模式支撑以筛选和提取有价值的信息。
自然语言处理在医学领域的应用提高了医疗数据的利用效率及医疗决策的准确性。半自动标注模型可以自动完成标注字段的词义积累,实现专科专病队列的构建以及诊疗数据的深度治理。电子健康记录的分析可以帮助医生更好地了解患者的病情和治疗历史,从而做出更准确的诊断并制定个性化的治疗方案。然而,在医学领域自然语言处理的应用面临一些挑战。医学相关文本通常具有特定的术语和复杂的语义关系,需要专业领域的知识才能充分理解并处理。此外,医学概念复杂导致数据标注工作周期长、成本高,标注工作复杂且耗时,也限制了模型的训练和应用。
医学影像人工智能的应用涉及放射影像、超声影像和病理图像等不同领域的研究,覆盖肺部、乳腺、心血管等多个部位,以及脑肿瘤、脑卒中等多种类型的疾病,还包括一些特定应用,如骨龄检测。医学影像人工智能可以辅助诊断肺结节、乳腺癌和脑肿瘤等疾病。然而,医学影像人工智能仍然面临挑战,如伪象识别能力相对较弱,需要优化和提升深度学习算法,以提高影像解读的准确性和稳定性;需要进行临床验证和规范评估,确保人工智能产品的安全性和有效性。
人工智能在药学领域的应用可以促进药物研发设计。基于深度神经网络方法预测分子结构与活性之间的关系、提取靶标和药物的序列特征等,可辅助药物发现和药物剂量优化。然而,人工智能辅助药物研发也同样面临一些挑战:深度学习模型通常被视为“黑盒”,难以解释其决策和推理过程,而在药物领域,可解释性是关键性问题,研究人员需要了解模型如何做出预测和决策才能信任并采纳模型的结果。此外,由于研发数据的质量偏差,人工智能模型可能受到数据不平衡和样本差异性的影响,导致模型的泛化能力受限,无法在真实世界中推广和应用。
在应用深度学习等人工智能技术进行训练时,需要海量的健康医疗数据支持,然而这些数据往往包含大量的患者个人信息,可能导致个人信息被获取,造成身份盗窃、个人隐私侵犯甚至潜在的社会工程攻击。因此,在医学人工智能应用过程中,需要高度关注健康医疗大数据的安全性,避免出现黑客攻击和数据泄露等安全问题。