您当前的位置:检测资讯 > 科研开发
嘉峪检测网 2025-03-13 12:30
在评估 GPU 性能时,通常首先考察三个指标:图形工作负载的纹理率(GPixel/s)、浮点运算次数(FLOPS)以及它们能处理计算和AI工作负载的每秒 8-bit tera 运算次数(TOPS)。这些关键数据,结合面积数据、功耗估算和通用功能集,帮助 SoC 设计师比较不同系统配置的性能。
然而,这些指标仅提供了理论性能,并不总是能够很好地反映实际性能。没有任何 GPU 能够始终以100%的利用率运行,因此下一步是探索GPU在实际应用中的特定工作负载性能,通常以每秒帧数(FPS)来衡量,并考虑整体GPU利用率。像Manhattan和Aztec这样的基准测试为实际图形性能提供了一个有用的指南(尽管它们本身并不能完全代表典型的应用程序)。
通常在这个阶段,不同的GPU架构会产生令人惊讶的结果。那些更擅长将理论性能转化为实际性能的架构会脱颖而出,提供远高于其标称TFLOPS预期的帧率(FPS)。
为什么FPS/TFLOPS很重要?
通常来说,具有更高TFLOPS的GPU需要更大的硅片面积和更高的功耗。如果一个较小的GPU能够提供与理论上更强大的GPU相同的实际性能,设计师就需要选择:要么以更低的成本提供相同的性能,要么保持成本不变但将额外的性能或效率交给最终用户。
基于此,理解GPU的性能效率是了解GPU在终端设备中表现的重要部分。
Imagination 的 PowerVR 架构经过数十年的优化,已成为市场上性能最为高效的嵌入式 GPU IP。本文将概述关键的硬件和软件优化,帮助 Imagination 的 GPU 实现比竞争对手的嵌入式产品高出两倍的 FPS/TFLOPS 性能。
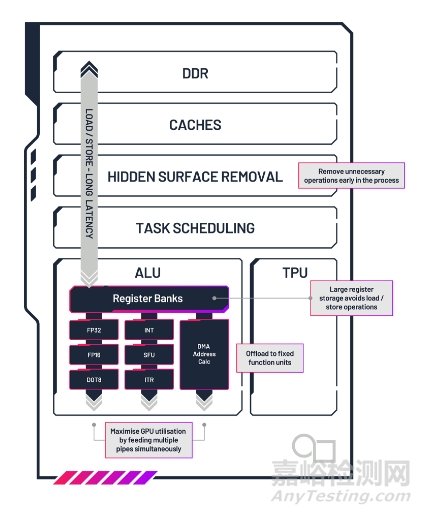
1. 大容量、响应迅速的寄存器存储
Imagination GPU 的每个算术逻辑单元(ALU)内都有非常大的寄存器存储,一般为 512KB,通常是竞争对手嵌入式 GPU 设计的两倍。这使得工作负载可以避免从主GPU内存进行长时间的加载/存储操作,这些操作可能会延迟处理工作,从而对GPU利用率和效率产生负面影响。
ALU中的寄存器体设计得允许同时访问多个寄存器。这意味着在每个周期中,ALU内的多个单元都可以执行任务。例如,FP32操作可以与复杂操作并行处理,而无需排队等待内存访问。大多数其他嵌入式GPU架构在寄存器访问方面存在限制,这会导致数据需要额外的周期来获取,从而造成处理停滞。
Imagination GPU设计可同时处理多个工作负载。这意味着当需要进行加载/存储时,可以通过替代操作填补处理暂停,从而有效避免延迟问题。
2. 专用模块卸载主ALU工作
Imagination 的ALU包含多个固定功能块,使 GPU 能够将冗长的任务(如地址计算)从主ALU 卸载,从而使它们可以自由处理一般工作负载。相比之下,大多数其他嵌入式 GPU 提供商通过 INT32 ALU模拟地址计算和复杂任务,降低了整体 GPU 性能效率。
3. 整体 GPU 架构效率
由于其延迟渲染技术,PowerVR架构自问世以来一直是GPU效率的领导者。在流水线的早期阶段,Imagination GPU 会全面分析每一帧,确定哪些片段是可见的,并仅处理用户可以看到的部分。通过尽早移除不必要的操作,Imagination GPU降低了功耗并提高了性能效率。其他嵌入式GPU架构仍然处理比必要更多的片段,浪费宝贵的计算资源和带宽,从而需要更多功耗。
4. 软件最大化GPU利用率
虽然我们主要从图形角度讨论性能效率,但上述内容同样适用于计算和 AI 应用。为了进一步提高 AI 工作负载的性能效率,Imagination 提供了一套高度优化的计算库(imgNN、imgBLAS、imgFFT),用于常见的运算操作,使程序员能够最大化 GPU 利用率。
所有这些特性的结果不言而喻。在下图的所有图形工作负载中,Imagination GPU 的 FPS/TFLOPS超过了同等面积的嵌入式竞争对手设计。在某些情况下,性能效率是其他GPU的两倍。
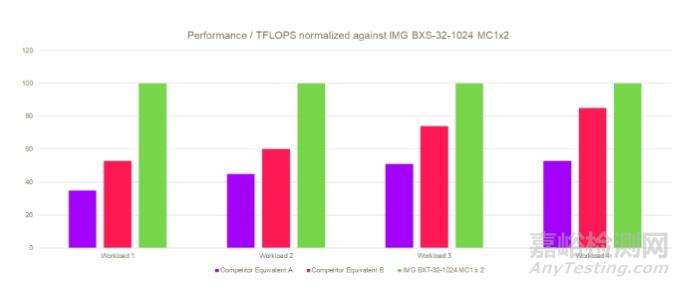
图注:基于Imagination内部数据。所有竞争设备以低时钟频率运行,以避免主机 CPU 和系统瓶颈,以便更纯粹地了解竞争 GPU 的能力。
GPU性能在所有细分市场上都在蓬勃发展,不仅用于图形体验,在 AI 时代,还将其用作灵活的并行计算处理器。硬件设计师有两种选择来提供这种额外的性能:一种是简单地构建一个具有更高理论TFLOPS的GPU;另一种选择是选择一个理论TFLOPS较低但高性能效率的 GPU。

来源:Imagination Tech


